This page provide documentation about the commands provided by OTAWA: More...
This page provide documentation about the commands provided by OTAWA:
- dumpcfg Command
- mkff Command
- odec Command
- odfa Command
- odisasm Command
- oipet Command (deprecated)
- opcg Command
- ostat Command
- otawa-config Command
- owcet Command
dumpcfg Command
This command is used to output the CFG of a binary program using different kind of output.
- SYNTAX
- dumpcfg first loads the binary file then compute and display the CFG of the functions whose name is given. If there is no function, the main functions is dumped.> dumpcfg options binary_file functions1 function2 ...
Currently, dumpcfg provides the following outputs:
- -S (simple output): the basic blocks are displayed, one by one, with their number, their address and the -1-ended list of their successors. !icrc1# Inlining icrc10 10000368 100003a4 1 -11 100003a8 100003b0 3 2 -12 100003b4 100003b4 4 -13 100003b8 100003c8 6 5 -14 1000040c 10000418 7 -15 100003cc 100003e8 8 -16 100003ec 100003f8 8 -17 1000041c 10000428 9 -18 100003fc 10000408 1 -1
- -L (listing output): each basic block is displayed starting by "BB", followed by its number, a colon and the list of its successors. Its successors may be T(number) for a taken edge, NT(number) for a not-taken edge and C(function) for a function call. # Function main# Inlining mainBB 1: C(icrc) NT(2)main:10000754 stwu r1,-32(r1)10000758 mfspr r0,2561000075c stw r31,28(r1)10000760 stw r0,36(r1)...BB 2: C(icrc) NT(3)1000079c or r0,r3,r3100007a0 or r9,r0,r0100007a4 sth r9,8(r31)100007a8 addis r9,r0,4097...BB 3: T(4)10000808 or r0,r3,r31000080c or r9,r0,r010000810 sth r9,10(r31)10000814 addi r3,r0,010000818 b 1BB 4:1000081c lwz r11,0(r1)10000820 lwz r0,4(r11)10000824 mtspr 256,r010000828 lwz r31,-4(r11)1000082c or r1,r11,r1110000830 bclr 20,0
- -D (dot output): the CFG is output as a DOT graph description.
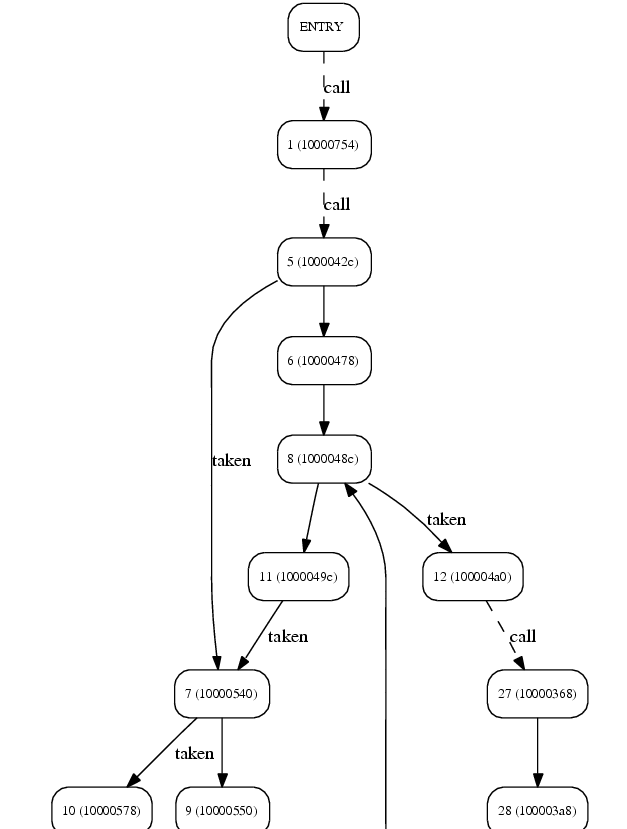
- -X or –xml (XML output): output a CFG as an XML file satisfying the DTD from $(OTAWA_HOME/share/Otawa/data/cfg.dtd .
dumpcfg accepts other options like:
- -a – dump all functions.
- -d – disassemble the machine code contained in each basic block,
- -i – inline the functions calls (recursive calls are reduced to loops),
- -v – verbose information about the work.
oipet Command
oipet allows to use WCET IPET computation facilities of OTAWA. Currently, you may only choose the algorithm for instruction cache support:
- ccg for Cache Conflict Graph from Li, Malik, Wolfe, "Efficient microarchitecture modelling and path analysis for real-time software", Proceedings of the 16th IEEE Real-Time Systems Symposium, 1995.
- cat for categorization approach (an adaptation to IPET of Healy, Arnold, Mueller, Whalley, Harmon, "Bounding pipeline and instruction cache performance," IEEE Trans. Computers, 1999).
- cat2 for categorization by abstraction interpretation (Ferdinand, Martin, Wilhelm, "Applying Compiler Techniques to Cache Behavior Prediction.", ACM SIGPLAN Workshop on Language, Compiler and Tool Support for Real-Time Systems, 1997) improved in OTAWA.
And the algorithm to handle the pipeline:
- trivial : consider a scalar processor without pipeline with 5 cycle per instruction,
- sim : use a simulator to time the program blocks,
- delta : use the simulator and the delta approach to take in account the inter-block effects as in J. Engblom, A. Ermedahl, M. Sjoedin, J. Gustafsson, H. Hansson, "Worst-case execution-time analysis for embedded real-time systems", Journal of Software Tools for Technology Transfer, 2001,
- exegraph : use the execution graph to time blocks as in X. Li, A. Roychoudhury, T. Mitra, "Modeling Out-of-Order Processors for Software Timing Analysis", RTSS'04.
- Syntax
This command compute the WCET of the given function using OTAWA IPET facilities. If no function is given, the main() function is used.
- Generic Options
- -I, –do-not-inline – cause to not inline functions for the WCET computation. Consider that this option may save computation time but, conversely, may reduce the WCET accuracy.
- –ilp solver – select the ILP solver to use (currently lp_solver (V4) or lp_solve5).
- Cache Management Options
- -c path, –cache=path – load the cache description from the file whose path is given.
- -f path, –flow-facts=path – use the given flow fact file,
- -i method, –icache=method – selects how the instruction must be managed. The method may be one of none, ccg, cat, or cat2.
- -l, –linkedblocks – enable LinkedBlocksDetector (cat2 only)
- -p, –pseudounrolling – enable Pseudo-Unrolling (cat2 only)
- -P type, –pers=type – select persistence type for cat2: multi, outer, or inner (default to multilevel).
- Pipeline Management Options
- -D depth, –delta=depth – select the depth of the delta algorithm, that is, how many blocks are used to compute inter-blocks effects (default to 4). Bigger is the depth, better is the accuracy but longer is the computing time.
- -p path, –processor=path – load the processor description from the file whose path is given.
- -t method, –bbtiming=method – selects the method to time the blocks. The method may be one of trivial, sim, delta, exegraph or paramexegraph.
- Dump Options
- -C, –dump-constraints=output_kind – dump the constraints that has been used to compute the WCET. The output_kind may be "lp" for lp_solve compatible output (suffixed by ".lp") or "html" for HTML output.
- -G, –dump-graph – for each function involved in the task, generate a file named function_name.ps containing the graph of the processed functions in DOT file format.
- -o, –output prefix – prepend the given prefix to the dump files names.
- -T, –dump-time – output statistics about time and execution count of BB.
opcg Command
opcg is a simple OTAWA tool to display the Program Call Graph (PCG) of a binary program.
- Syntax
This program output in postscript the PCG of a binary program rooted by the given function or, as a default, by the "main" function.
The output file use the entry function name where the file type extension is appended. If you do not select a special file output and no entry function, the output file is named "main.ps".
The options includes:
- -I|–no_intern – do not dump C internal functions (starting by '_' in the PCG).
- -c|–chain function – bound the PCG to network between the entry function and the given function (useful when the PCG is too big).
-o|–output type – select the type of output (the type may be one of ps, pdf, png, gif, jpg, svg, dot).
ostat Command
OStat displays some statistics - average, maximum - about a binary file:
- basic block count,
- basic block sizes,
- memory access instructions count,
- branch instructions count.
- SYNTAX
- $ ostat binary_file function1 function2 ...
OStat displays statistics about the given binary file for the requested functions. If no function is provided, the main() function is used.
Options consists of :
- -t: scan the full calling tree whose root is the processed function,
- -s: display statistics in short form (no more information labels),
- -o: display overall statistics including all processed functions.
- Example
owcet Command
owcet command allows to compute WCET of an application using a script provided for a particular architecture implementation. It provide full power of OTAWA framework including selection of architecture-dependent plugin and fine-tuned computation scripts.
- Syntax
The EXECUTABLE_PATH must be the path of the executable file to compute WCET for. This executable file must be in a machine language understood by OTAWA (currently OTAWA supports PowerPC, ARM, Sparc, HCS12 and partly TriCore).
The optional TASK_ENTRY designs the function to compute the WCET for and usually matches a task in the real-time applications. If this parameter is not given, the main function is used.
The SCRIPT_PATH is the path of the file containing the script. These file are usually found in $OTAWA_HOME/share/Otawa/scripts. When an architecture plugin is installed, it provides usually its own script.
Other options includes:
- -p, –param ID=VAL: several parameters with this form may be passed; these definition are used to pass parameters to the script and the supported ID depends on the launched script (see its documentation for more details),
- -f, –flowfacts PATH: OTAWA can not automatically found loops so this options is used to design the file containing loop bounds; supported formats includes .ff or .ffx (Flow Facts). Flowfacts allows also to pass specific configuration for the flow execution of a program.
- Hints
Real-time systems do not usually perform formatted output as printf family of functions but such a function are often used in case of error. Usually formatting performed by printf is big and complex piece of code that, in the case we take it into account in the WCET computation, would dominate the execution time and drive to a very overestimated WCET. To avoid this, you can command to OTAWA to ignore them without recompiling your application. Just create a file named YOU_EXECUTABLE.ff and write inside:
You can do the like with any function disturbing your computation. You can find in F4 : Flow Facts File Format more details about the commande .ff files. You may also use XML format called .ffx (see Flow Fact XML format).
mkff Command
This command is used to generate F4 file template file template (usually suffixed by a .ff) to pass flow facts to OTAWA. Currently, only constant loop bounds are supported as flow facts. Look the F4 : Flow Facts File Format documentation for more details.
- SYNTAX
- $ mkff binary_file function1 function2 ...
mkff builds the .ff loop statements for each function calling sub-tree for the given binary file. If no function name is given, only the main() function is processed.
The loop statement are indented according their depth in the context tree and displayed with the current syntax:
The "?" question marks must be replaced by the maximum loop bound in order to get valid .ff files. A good way to achieve this task is to use the dumpcfg Command command to get a graphical display of the CFG.
- Example
- $ mkff fft1// Function mainloop 0x100006c0 ?;// Function fft1loop 0x10000860 ?;loop 0x10000920 ?;loop 0x10000994 ?;loop 0x10000a20 ?;loop 0x10000bfc ?;loop 0x10000d18 ?;loop 0x10000dc0 ?;// Function sinloop 0x10000428 ?;loop 0x1000045c ?;loop 0x10000540 ?;
- Other information
mkff has the ability to produce automatically other commands to handle problematic or exotic flow fact structures:
- false control instruction (branching to the next instruction to get the PC values on some architecture),
- undirect branches (switch-like construction, function pointer calls),
- non-returning functions (like exit(), _exit()),
- problematic initialization (like __eabi on EABI based platforms, _main for tricore).
- Usage
- In very complex programs, it may be required to launch mkff several times.
As mkff may detect unsolved indirect branches (function pointer call or swicth-like statements, the first phase consist to fill this kind information and to relaunch mkff to scan unreachable parts of the program. Possibly, some parts may also be cut to tune the WCET computation.
As an example, we want to build the flow facts of the program xxx.
- generate a first version:
{$ mkff xxx > xxx.ff}, - if required, fix the non-loop directives and removes the loop directives,
- generate a new version:
{$ mkff xxx >> xxx.ff}, - while it remains unfixed non-loop, restart at step 2.
In the second phase, you must fix the loop directives, that is, to replace the question marks '?' by actual loop iteration bounds.
odisasm Command
ODisasm disassemble a binary program and display information provided by the instruction loader, that is,
- instruction kinds,
- branch target (for control instructions),
- read and written registers,
- semantic instructions (when available).
This command is particularly useful when a loader is written. It allows to examine the information provided by the loader from the OTAWA run-time point of view and to find back possible errors.
- SYNTAX
- $ odisasm binary_file function1 function2 ...
The following are provided:
- -r, –regs: display register information,
- -k, –kind: display kind of instructions,
- -s, –semantics: display translation of instruction into semantics language,
- -t, –target: display target of control instructions
- -b, –byres: display bytes of instructions
- Example
- $ odisasm -ktr loop101800248 lwz r0,12(r31)read regs = r31written regs = r00180024c cmpi 7,0,r0,99kind = INT ALUread regs = r0 xerwritten regs = cr001800250 bc 4,29,-9target =read regs = cr0 ctrwritten regs =01800254 lwz r0,8(r31)read regs = r31written regs = r001800258 or r3,r0,r0kind = INT ALUread regs = r0 r0written regs = r30180025c addi r11,r31,32kind = INT ALUread regs = r31written regs = r1101800260 lwz r0,4(r11)read regs = r11written regs = r001800264 mtspr lr,r0kind = INTERNread regs = r0written regs = lr01800268 lwz r31,-4(r11)read regs = r11written regs = r31
odfa Command
ODFA allows to launch data flow analysis in a stand-alone way and to display the results. For the time being, only the CLP analysis is supported but more will be added later.
- SYNTAX
- $ odfa binary_file function1 function2 ...
The following options are provided:
- -c, –clp – perform CLP analysis,
- –before – display the data values before the basic blocks,
- –after – display the data values after the basic blocks,
- -s, –sem – display semantic instructions,
- -F, –filter – display filters (for the CLP analysis),
- -S, –stats – display statistics of the analysis,
- -C, –cfg – dump the CFG in .dot format (including data values),
- -r, –reg REGISTER=VALUE – add an initialization register.
otawa-config Command
This command provides useful information to compile an OTAWA application or a plugin.
- Syntax
- > otawa-config [OPTIONS] MODULES...
The following options are available:
- –cflags – output compilation C++ flags
- –data – output the OTAWA data path
- –doc – output the OTAWA documentation path
- –has-so – exit with 0 return code if dynamic libraries are available, non-0 else
- -h, –help – display the help message
- –list-ilps, –ilp – list ILP solver plugins available
- –libs – output linkage C++ flags
- –list-loaders, –loader list loader plugins available
- –modules, –list-modules list available modules
- –prefix output the prefix directory of OTAWA
- –procs, –list-procs – list available processor collections
- –version – output the current version
- –scripts – output the scripts path
- –list-scripts – output the list of available scripts
- -r, –rpath – output options to control RPATH on OS supporting it.
- -p, –plugin ELD_FILE – ouput linkage options for a plugin for the given ELD file.
- -i, –install – output the directory where installing a plugin.
- –oversion – output version of OTAWA.
odec Command
This command is an helper to implement a new loader plugin. Program decoding is a complex and time-consuming task implemented by otawa::TextDecoder analyzer. It uses the decoding ability of the loader to follow execution paths of the program. Because of the complexity of this work, a lot of inconsistencies are silently ignored by the decoder but these issues could be good indications about something wrongly done by the implemented loader.
As it should to costly to support verbosity switch in the decoder, this command proceed as the decoder but provides as much information on the process impossible. This makes easier the understanding and the retrieval of an error from a loader.
