3 Working with CFG
This tutorial will present $(OTAWA)'s classes set up to implement CFG and how to implement analysis algorithm working on the CFG .
3.1 CFG Definition
Basically, a CFG represents the program a graph \(G = \langle V, E, \alpha, \omega \rangle\) where:
\(V\) is the set of BB (Basic Block) composing the program,
\(E\) is the set of edges \(v \to w\) between BB,
\(\alpha \in V\) is the BB representing the entry in the program,
\(\omega \in V\) is a unique BB representing the end of the program.
For most of them, BB are list of instructions as found in the binary form of the program with two restrictions:
A BB can contain at most 1 branch instruction and, in this case, it is the last one.
Branch instruction of the program can only branch to an instruction that is the fist of BB.
These restrictions ensures there is a unity of execution of instructions in the BB: when the first instruction is executed, all instruction of the BB will be next executed once and in the order of the BB.
An alternative to build CFG is to constrain to have 1 instruction per BB. The expressivity is the same with our CFG implementation but the graph is much bigger. Having BB made of a list of instructions meeting the constraints above allows to reduce the graph size and to preserve the execution unity property.
CFG are very good to represent the control flow of a function/subprogram but are less precise to represent a whole program made of several functions callong each other. In this case, we can use a PCG (Program Call Graph) discussed in a later tutorial. For now, we have just to keep in minde that a program is, in reality, made of a collection of CFG with a special CFG that is the first function to be executed (it is called main in C in classic programs).
OTAWA is able to generate and to display with the command:
$ dumpcfg -Wds PROGRAM.elf
This can be applied to binaries coming with these tutorials. To get a graphical view of the CFG, you can use our tool (installed as an extension of OTAWA) called ``obviews``:
$ obviews PROGRAM.elf
Below is an example of the displayed CFG with source and disassembly:
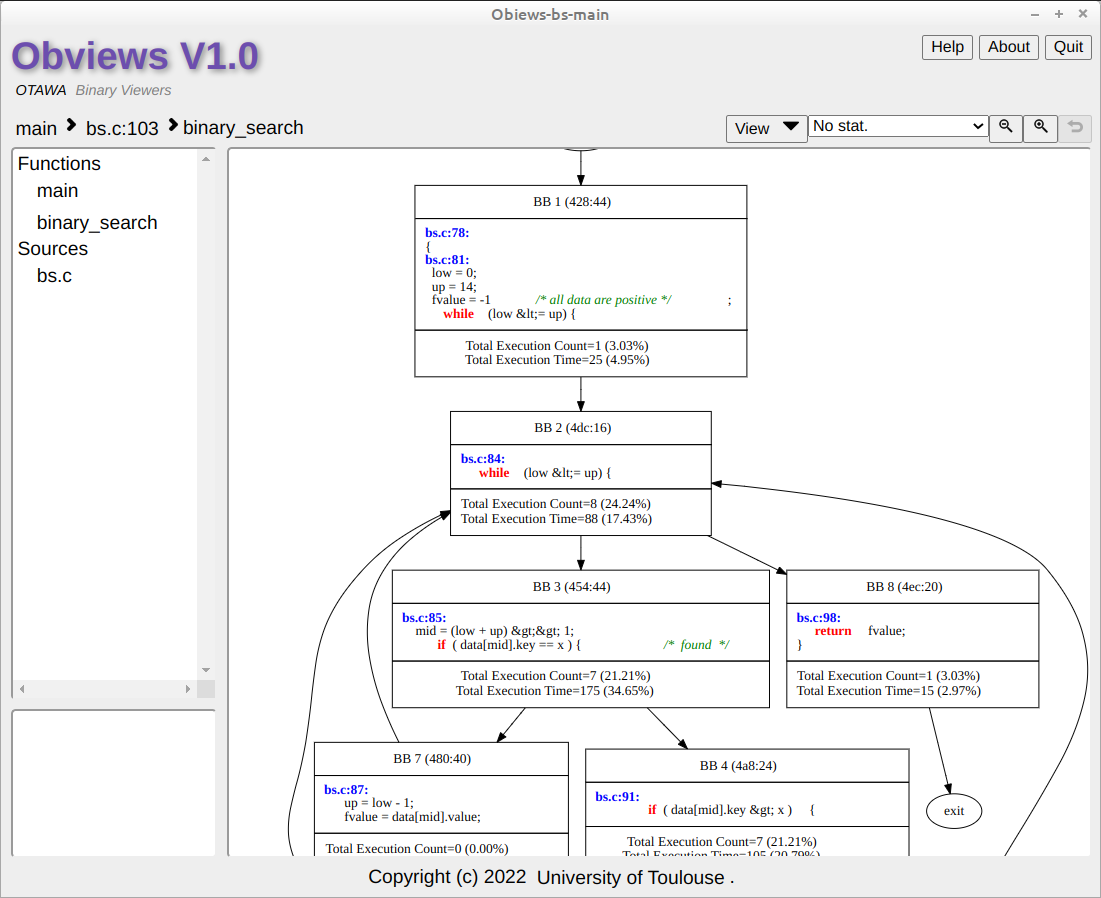
3.2 CFG in OTAWA
OTAWA provides different ways to build the CFG of the program but the simplest one is to require the feature otawa::COLLECTED_CFG_FEATURE:
#include <otawa/cfg/features.h> WorkSpace *ws = ...; ws->require(COLLECTED_CFG_FEATURE);
Obtaining the CFG collection is performed this way:
const CFGCollection *cfgs = COLLECTED_CFG_FEATURE(ws).get();
A CFGCollection is really just a list of CFG with an additional function entry() that return the entry CFG of the program.
In turn, a CFG is just like the definition given in the previous section:
Notice that, in OTAWA, entry and exit BB are not real BB: they do not contain any instruction and does not match each memory area in the code. But we are sure they are unique: this may help for some graph algorithms.
In fact, BB are implemented by class otawa::Block and are derived into specific subclasses according to their nature:
Block::isEntry(), respectively, Block::isExit() returns true for entry, resp. exit, BB .
Block::isBasic() returns true for real BB (class otawa::BasicBlock) with a list of instruction and the instance can be obtained with the function Block::toBasic()).
Block::isSynth() returns true for BB representing synthetic BB i.e. a function call (class otawa::SynthBlock) and the instance can be obtained with the function Block::toSynth().
Whatever the considered BB, they share the property to be involved in the graph and consequently, the in-going or out-going edges can be visited:
Block *b = ...; for(auto in: b->inEdges()) ...; for (auto out: b->outEdges()) ...;
The edges – of class otawa::Edge, are very simple:
Edge::source() gets the source BB,
Edge::sink() gets the sink BB. In addition, they can be qualified with:
Edge::isTaken() is true if it results from a branch instruction,
Edge::isNotTaken() is true it results from a not-taken conditional branch or from a sequential code execution,
Edge::isCall() is true if it represents a subprogram call,
Edge::isReturn() is true if it represents a subprogram call return.
A BasicBlock is basically a list of instructions that can be explored in the usual way in C++:
BasicBlock *bb = ...; for(auto inst: *bb) ...;
In addition, this class provides convenient accessors:
BasicBlock::first() to quick access to the first instruction,
BasicBlock::count() counts the number of instructions in the BB,
BasicBlock::control(), if any, returns the control instruction at the end of the BB.
Finally, a SynthBlock objects represent a subprogram call:
SynthBlock::callee() – the called CFG (can a null pointer if the callee subprogram cannot be found).
SynthBlock::caller() – the CFG performing the call.
SynthBlock::callInst() – the instruction performing the call.
Notice that the SynthBlock objects to the same callee subprogram are chained together. This means that a CFG can list all the BB that call it:
CFG *g = ...; fopr(auto caller: g->callers()) cout << "my caller is " << caller << io:endl;
Using these functions, it is very easy, for instance, to create an application that dumps the call graph:
void dumpCall(CFG *g, string indent) { cout << g << io::endl; indent = indent + "\t"; for(auto v: *g) if(v->isSynth()) { cout << indent << "-> "; dumpCall(v->toSynth()->callee, indent); } }
3.3 Loops in the CFG
When processing graph, the most complex structure to manage are loops. Loops are difficult to identify and requires special processing to avoid endless run of the graph algorithm.
If OTAWA cannot cope with algorithm problems, it is able to identify loops and provide a robust interface to work with loops. First, the identification of loop is made with feature otawa::LOOP_INFO_FEATURE:
#include <otawa/cfg/features.h> WorkSpace *ws = ...; ws->require(LOOP_INFO_FEATURE);
Then the top-level loop of a CFG – the CFG itself in fact that is viewed as loop can be obtained with:
CFG *g = ...; Loop *top_loop = Loop::of(g);
Another way to obtain the contained loop of a particular BB:
Block *v = ...; Loop *container_loop = Loop::of(v);
Once the top-level obtained, it easy to navigate in the hierarchy of loops:
subLoops() gets the sub-loops of the loop,
parent() gets the parent loop of the current loop,
isLeaf() returns true if the current has no sub-loop,
isTop() returns true if the current loop is the top loop.
The BB and the edges composing the loop can be explored with:
blocks() gets the BB composing the loop,
header() gets the BB head of the loop,
entries() gets the edges entering the loop,
exist() gets the edges leaving the loop,
backs() gets the back edges i.e. edges closing the loop.
Notice that we usually consider loops with only onde head BB. But this is not necesserally the case with graph extracted from the binary code. This loops with several headers are sometimes irregular loops.
While loops are hard to process, irregular loops are even more harder. Yet, the CFG can be restructued, by copying block, to remove such loops. This is done, in OTAWA, by invoking the feature otawa::REDUCED_LOOPS_FEATURE.
3.4 Maintaining data linked to BB
The analyses that are applied CFG often needs to link data with BB. There is mainly three main strategies to do this.
First, using the property system: an identifier is declared with the type of data to link and is then hooked with the data to the BB:
typedef ... data_type_t; p::id<data_type_t> DATA_ID(...); ... Block *v = ...; data_type_t data = ...; DATA_ID(v) = data;
The property system are convenient because it easy to use in programming but it is (a) relatively memory space consuming and (b) relatively slow to access. It works better for data with a sparse coverage on the CFG. Another problem is that cleaning the CFG collection from the added data requires to traverse all CFG and BB .
Another solution could be the use of map between blocks and data. For example,
#include <elm/data/HashMap.h> typedef ... data_type_t; HashMap<Block *, datatype_t> map; ... Block *v = ...; data_type_t data = ...; map.put(v, data);
Although working, this approach has roughly the same access drawbacks as the property approach. In the opposite, the deletion problem is solved.
A better solution is maybe the use of a unique index, called its id, that is stored with each BB. In addition, the CFG collection provides also a count of all BB in all CFG of the collection. With this id, it is easy to declare a big array for all BB and to use the id to access the corresponding data:
const CFGCollection *cfgs = ...; typedef ... data_type_t; data_type_t array[cfgs->countBlock()]; ... Block *v = ...; data_type_t data = ...; array[v->id()] = data;
3.5 Exercise
The dominator problem consists, in graph theory, to compute the set of BB that dominates a particual BB.
A BB \(v \in V\) is dominated by a BB \(w \in \), denoted \(w ~dom~ v\), if all paths from the graph entry \(\alpha\) to \(v\) traverse \(w\). With this property, the execution of \(v\) is always preceded by the execution of \(w\). We call the set of BB dominating \(v\) \(DOM(v)\).
There are several methods to compute \(DOM(v)\) but one, very simple, is based on iDFA (iterative Data Flow Analysis). In iDFA, the value associated to each BB are sets and the problem, \(DOM(v)\) in this case, is expressed as point-fix of a set of set equations for each BB of the CFG.
For the dominator problem, the equations are (for each \(v \in V\)):
\(DOM(v) = \bigcap_{w \in PRED(v)} OUT(w)\)
\(OUT(v) = DOM_v \cup \{ v \}\)
With \(PRED(v)\) the set of predecessors of \(v\) and \(DOM(v)\) and \(OUT(v)\) initialize to \(V\). To get the solution, one has to repeat the calculation until a fix point is obtained. This means that we have to compare new-computed \(DOM(v)\) and new-computed \(OUT(v)\) and to stop when there is no more change.
To represent the set of vertices, we propose (a) to assume there is no more than 64 BB in the CFG and (b) to use bits of a 64-bit word (type elm::t::uint64). The following set operation can be performed this way:
the empty set is t::uint64(0UL),
the full set is t::uint64(-1L)
adding \(v\) to set \(s\): s | (1 « v.index() ),
testing if \(v\) is in the set \(s\): s & (1 « v.index() ),
performing union of two sets \(s_1\) and \(s_2\): s1 | s2,
performing intersection of two sets \(s_1\) and \(s_2\): s1 & s2.
For a more robust solution, the class elm::BitVector exploits the same tricks but on much more big number of bits.
otawa::BasicBlock
otawa::Block
otawa::CFG
otawa::CFGCollection
otawa::COLLECTED_CFG_FEATURE
otawa::Edge
otawa::Loop
otawa::REDUCED_LOOPS_FEATURE
oatwa::SynthBlock